DeepSeek-R1: The Open-Source AI That Thinks Like OpenAI’s Best!
Published:

For years, the AI community has chased a moonshot: creating open-source models that rival the reasoning power of giants like OpenAI. Today, that moonshot just landed. DeepSeek-R1, a new open-source language model released under the MIT license, not only matches OpenAI’s cutting-edge “o1” models in reasoning benchmarks — it does so at a fraction of the cost. Let’s unpack why this matters and how DeepSeek pulled it off.
📌The DeepSeek Breakthrough: AI That Thinks Step-by-Step
DeepSeek-R1 is part of a new class of “thinking models” that mimic human-like reasoning. Unlike traditional language models that generate answers in a single pass, DeepSeek-R1 breaks problems down, debates alternatives, and self-corrects — all visible in its “Chain of Thought” outputs. For example, when asked “How many Rs are in ‘strawberry’?”, the model writes:
“First, I’ll spell it out: S-T-R-A-W-B-E-R-R-Y. Now I’ll count: positions 3 (R), 8 (R), and 9 (R). Wait, is that right? Let me check again… Yes, three R’s.”
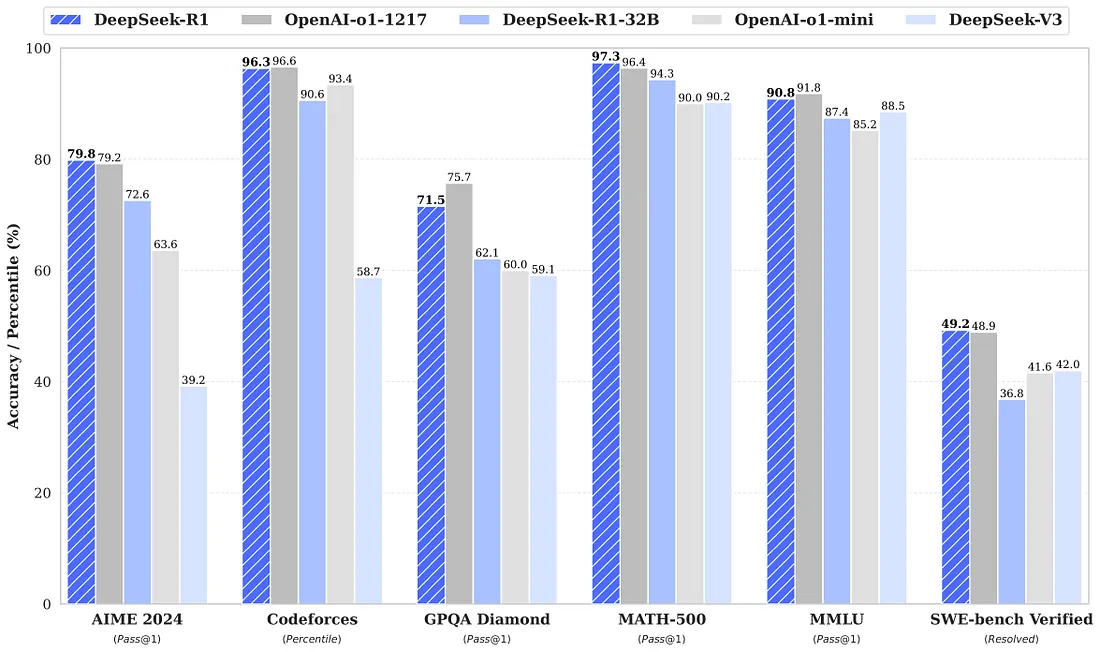
This isn’t just a parlor trick. On benchmarks like AIME 2024 (a math competition), DeepSeek-R1 outperforms OpenAI o1, and it’s neck-and-neck on coding tasks (Codeforces) and real-world problem-solving (SWE-Bench). Even more impressive? It does this while being 10x cheaper than OpenAI’s API (0.14vs.0.14vs.15 per million tokens for outputs).
📌How They Built a “Thinking Machine”
The team tackled a critical problem: How do you teach an AI to reason without massive human feedback? Traditional methods rely on supervised fine-tuning (SFT), where humans manually craft examples. DeepSeek’s answer? Reinforcement Learning (RL) on steroids.
✅ DeepSeek-R1-Zero: The AlphaGo of Language Models The first model, R1-Zero, learned purely through trial and error using a technique called Group Relative Policy Optimization (GRPO). Here’s the twist:
- No supervised data: Unlike OpenAI’s o1, R1-Zero skipped SFT entirely. It started with raw pretraining data and learned by generating answers, comparing them in groups, and rewarding correct reasoning.
- Self-evolution: Over time, the model taught itself to spend more “thinking time” on harder problems. In one experiment, it generated 3x longer reasoning chains for complex math questions — without being told to do so.
✅ DeepSeek-R1: Fixing the Quirks
R1-Zero had flaws: its outputs were messy (mixing languages like English and Chinese) and hard to read. The team fixed this with a “cold start” phase:
Mini-SFT: They fine-tuned the model on a tiny dataset (just 1,000 examples) of high-quality reasoning chains.
Two-stage RL: First, they trained for accuracy and format. Then, they added a second RL stage to align with human preferences (e.g., helpfulness, safety).
The result? A model that thinks clearly, stays on-task, and even outperforms GPT-4o on coding benchmarks like LiveCodeBench.
📌The Secret Sauce: Technical Innovations
👉Group Relative Policy Optimization (GRPO)
Instead of using a separate “critic” model (like OpenAI’s PPO), GRPO compares multiple responses in a group. Analogy: Imagine students working on a math problem. The teacher rewards the group based on relative performance, not absolute scores. This pushes the model to self-improve competitively.
👉Reasoning-Oriented Rewards
The reward function prioritized two things:
- Accuracy: Did the final answer match ground truth?
- Format: Did reasoning steps use
tags properly? This forced the model to structure its thoughts logically.
👉Distillation: Making Bigger Models Obsolete DeepSeek distilled R1’s knowledge into smaller models (7B to 70B parameters) using SFT. The results shocked even the team:
- A 14B-parameter model outperformed Qwen-32B on coding tasks.
- The 70B distilled model nearly matched GPT-4 on mathematical reasoning (MATH 500).
📌Benchmarks
📌Why This Changes Everything
Open Source Wins: Developers can now run GPT-4-level reasoning locally or via DeepSeek’s API at a 90% lower cost.
The “Aha Moment” for AI: DeepSeek-R1-Zero demonstrated that models can self-develop reasoning strategies. One example: When stuck on a problem, it learned to backtrack and question its initial assumptions — a behavior never explicitly programmed.
Democratizing AI: By releasing weights and distillation recipes, DeepSeek lets anyone build specialized models. Imagine a coding assistant distilled from R1 but fine-tuned on your company’s codebase.
📌What’s Next? The Road Ahead
The team is already working on:
- Fixing language mixing: Ensuring outputs stay in one language.
- Prompt engineering: Reducing sensitivity to phrasing (e.g., “Let’s think step-by-step” vs. “Solve this”).
- Software engineering focus: Applying RL to tasks like debugging and CI/CD automation.
📌Final Thoughts
DeepSeek-R1 is proving to be a blueprint. By proving that open-source models can rival closed systems through innovative RL, it opens the floodgates for community-driven AI.
As the team writes:
“We didn’t teach the model how to think. We gave it the right incentives, and it taught itself.”
The era of accessible, reasoning-grade AI is here. And it’s open-source.
Try DeepSeek-R1 Now:
Hosted version: chat.deepseek.com
Weights & code: GitHub
Technical paper: DeepSeek-R1: Scaling Reasoning with Reinforced Evolution
What will you build with it?