
Understanding Interpretability!
Published:
Imagine standing before a vast, humming machine whose inner workings are hidden behind opaque panels. You can see the inputs going in and watch the outputs coming out, but what happens inside remains a mystery. This is how most of us experience modern deep learning models - astonishing, but ultimately black boxes. Mechanistic Interpretability (MI) is the research direction that seeks to pry open those panels and understand every cog and gear that drives a neural network’s decisions.
Why Go Beyond “What” to “How”?
Traditional interpretability tools - saliency maps, feature importance scores, LIME, SHAP, offer much value. They tell us which input features influenced a prediction. But they stop short of revealing how the network actually computes its answer. MI takes us from correlation to causation. It’s not enough to know that “the model looked at these pixels”; we want to know which neurons lit up, which circuits processed those activations, and in what order. We aim to rebuild the network’s computation in human-readable form, almost like pseudocode for a piece of software.
The Building Blocks of Understanding
Features
At the lowest level, a feature is a pattern the network learns to recognize - edges in an image, parts of speech in text, or textures in a scene. Early vision models revealed neurons that detect horizontal lines or the color red. In language models, some neurons spike in response to quotation marks or specific grammatical structures.Polysemantic Neurons and Superposition
Reality quickly gets messy: neurons often become “polysemantic,” meaning they respond to multiple, seemingly unrelated features. A single neuron might fire for both cat faces and car fronts. The superposition hypothesis suggests that networks pack more features into their finite set of neurons by overlapping representations. This means we can’t always point to one neuron and say, “That’s the cat detector.”Circuits
These are groups of neurons that collaborate to perform a function. A low-level circuit might detect edges and textures; a mid‑level one might combine those into “cat ears” or “wheel spokes”; a high‑level circuit might aggregate parts into entire object representations. By mapping these circuits, we start to see the network’s hierarchical processing pipeline.
Tools of the Trade: Causal Interventions
To move from association to causation, researchers employ activation patching and causal tracing.
Activation Patching: Run the model on a “clean” input and a “corrupted” version (e.g, an image with noise). Then, selectively replace activations in the corrupted run with those from the clean run. If swapping a particular layer’s activations restores the model’s performance, that layer must be causally critical for the task.
Causal Tracing: More broadly, this involves adding noise or making small interventions at various points in the network to see how the output changes. By systematically denoising or patching, we chart the flow of information and pinpoint the neurons and circuits that truly matter.
They remind me of induction heads in transformers, which enable in‑context learning by spotting repeated patterns in a sequence, or the “indirect object identification” circuit in language models that reliably pick out the right noun when completing a sentence.
Interpreting Vision Models and Vision–Language Models
While much of early MI work focused on language and synthetic tasks, vision has its own rich interpretability story — and it only gets more intriguing when you blend pixels with prose.
CNNs and Early Vision Models
Filter and Feature Visualization
By optimizing input images to maximally activate a single convolutional filter, researchers saw vivid edge‑detectors (horizontal, vertical), color blobs, and texture patterns emerge. These visualizations gave the first concrete peek into what early vision layers “look for.”Network Dissection
Utilizing human-labeled segmentation datasets, this method aligns each hidden channel’s activation map with known semantic concepts — clouds, wheels, faces — quantifying how well individual neurons act as detectors for interpretable features.
Vision Transformers (ViTs)
Attention‑Head Analysis
ViTs assign each patch of an image to multiple attention heads. By mapping where each head attends, researchers reveal fine‑grained spatial relationships and part‑based circuits.Circuit Discovery Causal patching in ViTs has uncovered middle‑layer “part” circuits (wheels, ears) and late‑layer “object” circuits (entire cat, complete car). Tracing these pathways shows a clear hierarchy:
pixels → edges → parts → whole objects.
Vision–Language Models (VLMs)
Adapter‑style VLMs like LLaVA inject CLIP embeddings as “soft prompts” into a frozen language model. The paper TOWARDS INTERPRETING VISUAL INFORMATION PROCESSING IN VISION-LANGUAGE (ICLR 2025) performed a suite of experiments to reveal three key mechanisms in LLaVA’s LM component.
Object‑Token Localization
Ablation of visual tokens corresponding to an object’s image patches causes object‑identification accuracy to drop by over 70%, whereas ablating global “register” tokens has minimal impact. This demonstrates that object information is highly localized to the spatially aligned tokens.Logit‑Lens Refinement
Applying the logit lens to visual‑token activations across layers shows that by late layers, a significant fraction of tokens decode directly to object‑class vocabulary (e.g., “dog,” “wheel”), despite the LM never being trained on next‐token prediction for images. Peak alignment occurs around layer 26 of 33, confirming that VLMs refine visual representations toward language‑like embeddings.Attention Knockout Tracing
Blocking attention from object tokens to the final token in middle‑to‑late layers degrades performance sharply, whereas blocking non‑object tokens or the last row of visual tokens has little effect. This indicates that the model extracts object information directly from those localized tokens rather than summarizing it elsewhere.
Together, these findings show that VLMs not only localize and refine image features but also process them through language‑model circuits in ways analogous to text.
Mechanistic vs. Post‑Hoc Interpretability
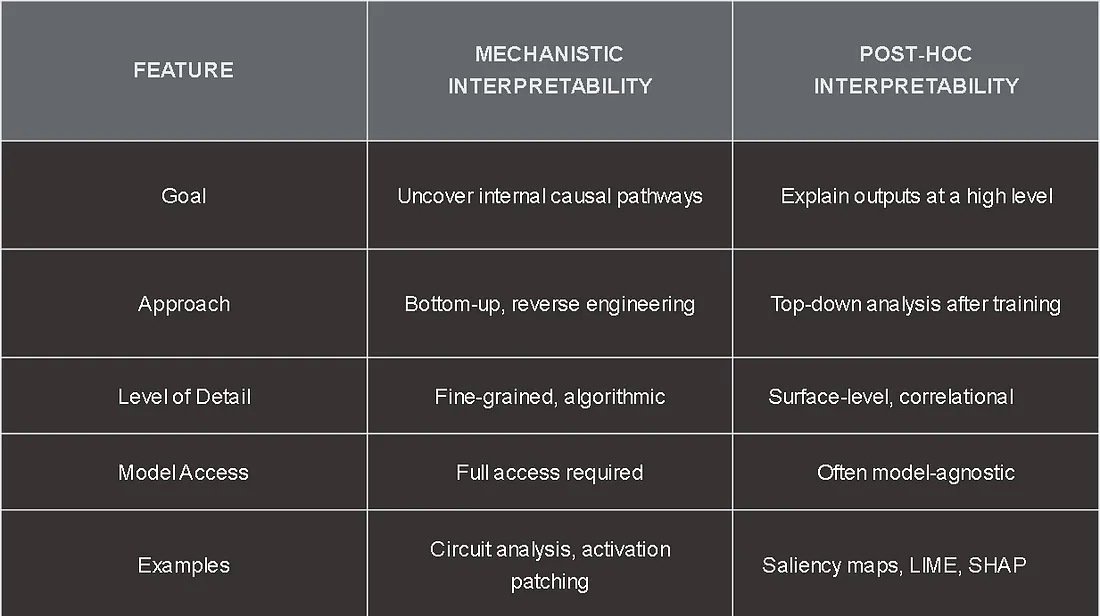
While post‑hoc methods remain invaluable for quick diagnostics and model‑agnostic checks, MI offers the deeper insights required for true transparency, safety audits, and targeted interventions.
Why It Matters
As AI systems increasingly shape critical decisions — from loan approvals to medical diagnoses - the stakes for understanding and controlling them could not be higher. MI promises to:
- Detect and Fix Bugs: By tracing the exact computations, we can locate flaws and ensure reliable performance.
- Uncover and Mitigate Bias: Identify circuits that encode undesirable biases and selectively dampen or retrain them.
- Ensure Alignment: Spot hidden objectives or misaligned goals before they manifest in harmful behaviors.
- Enable Trust: Offer regulators, practitioners, and the public a clear window into AI decision‑making.
Open Challenges and Future Directions
While Mechanistic Interpretability has delivered deep insights on small and medium‑scale models, several hurdles remain before it can crack the biggest and most consequential networks.
Scaling Analyses to Massive Models
Models with tens or hundreds of billions of parameters introduce a combinatorial explosion in the number of neurons, layers, and possible interactions. Manual circuit discovery simply doesn’t scale. New algorithms and tooling are needed to triage and prioritize which subnetworks to inspect first.Taming Superposition and Distributed Representations
When features share neurons in overlapping “superposed” embeddings, isolating a single concept becomes a puzzle. Likewise, distributed representations spread information across many units, making it hard to pinpoint “where” a feature lives. Methods for disentangling these overlaps — perhaps via sparse coding or novel regularization — are an active research direction.Automating Circuit Discovery
Today, much interpretability work still relies on human intuition to propose candidate circuits or features. To handle real‑world models, we need pipeline‑style systems that can automatically (1) identify interesting activation clusters, (2) group them into candidate circuits, and (3) run causal interventions to validate or reject them.Rigorous Evaluation and Faithfulness Metrics How do we know our interpretations truly reflect what the model does, rather than being cherry‑picked stories? Developing quantitative benchmarks and metrics, such as measuring how well a discovered circuit predicts behavior on held‑out data, or comparing alternative hypotheses, is critical for establishing trust in MI findings.
Extending to Multimodal and Continual Learning
As models begin to learn from streams of data across vision, language, audio, and beyond, and as they update continually in deployment, we must adapt interpretability methods to handle evolving representations and interactions across modalities.Intervention and Control
Ultimately, we want not only to understand models, but to steer them — repair bugs, remove biases, and enforce safety constraints. Building reliable “circuit surgery” tools that can disable or adjust specific mechanisms without unintended side effects is a long‑term goal.
Closing Thoughts
Mechanistic Interpretability is more than a technical challenge — it’s a philosophical shift. We are moving from treating neural networks as inscrutable oracles to viewing them as engineered artifacts whose inner workings can be laid bare, understood, and improved.
I think the journey is arduous, the puzzles are complex, and the road is long, but the destination — transparent, controllable, and trustworthy AI — is one we can all agree is worth striving for.
Links for Further Reading
- Mechanistic Interpretability for AI Safety A Review
- Open Problems in Mechanistic Interpretability
- Adaptive Circuit Behavior and Generalization in Mechanistic Interpretability
- From Neurons to Neutrons: A Case Study in Interpretability
- The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
For Vision
- Scale Alone Does not Improve Mechanistic Interpretability in Vision Models
- Towards Interpreting Visual Information Processing in Vision-Language Models
- PixelSHAP: What VLMs Really Pay Attention To
- Fill in the blanks: Rethinking Interpretability in vision
