Evolution and Magic of Attention!
Published:
TLDR;
- Transformers use attention to process entire sequences simultaneously, bypassing the limitations of sequential RNNs.
- Attention mechanisms work by comparing queries to keys and using the results to weight the values, allowing models to focus on relevant information.
- Multi-head attention, positional encodings, and residual connections are key design choices that make Transformers powerful and scalable.
- The evolution from RNNs to Transformers - sparked by early attention ideas - has paved the way for SOTA models in NLP, computer vision, and beyond.
Imagine you’re at a busy party - the so‐called “cocktail party effect.” You focus on a friend’s voice amidst the chatter. In ML, this ability to selectively “listen” is what attention mechanisms enable. Early neural networks struggled with long sentences and complex relationships. The concept of “Attention” first emerged in machine translation, where models had to decide which words to “focus on” to translate a sentence correctly.
🔸What Is Attention?
Imagine reading a complex paragraph: instead of trying to remember every single word equally, you naturally focus on the most relevant sentences to understand the meaning. In Transformers, each word (or token) is transformed into three vectors:
- Query (Q): Think of it as a question - what information is needed?
- Key (K): Think of it as an index - what pieces of information are available?
- Value (V): The actual content - the information that gets passed on.
The model computes how “compatible” a query is with each key using a dot product, scales the result (to prevent overly large numbers), and then applies a softmax function. This converts raw scores into probabilities (attention weights) that determine how much each word should contribute when forming a new representation. Mathematically, it looks like this:
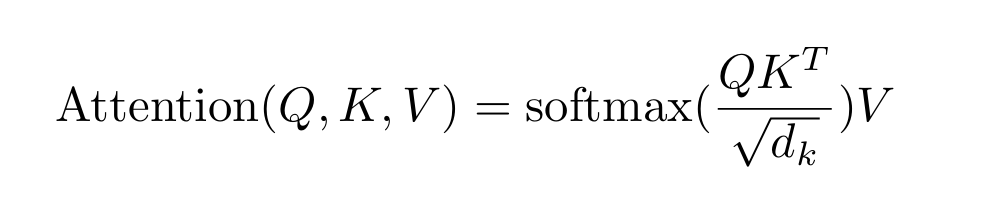
This self-attention mechanism means every word can “look at” every other word - capturing context, syntax, and even distant relationships that older models struggled to remember.
🔸Transformer Architecture

Encoder–Decoder Structure
The Transformer is built on a classic encoder–decoder model:
- Encoder: Processes the input sequence and converts it into a series of continuous, contextualized vectors.
- Decoder: Takes these vectors and generates the output sequence (e.g., translating a sentence).
Both parts are built from stacked layers that use attention and feed-forward networks, but they differ slightly:
- Encoder Layers: Use self-attention to let each token gather context from the entire sequence.
- Decoder Layers: Use masked self-attention (to prevent “peeking” at future tokens) and cross-attention to align with encoder outputs.
Multi-Head Attention
Rather than relying on a single attention function, the Transformer uses multi-head attention. It splits the queries, keys, and values into multiple “heads” so that different parts of the model can focus on different aspects of the input simultaneously.
Positional Encoding
Since Transformers process words in parallel (without a natural order), they add positional encodings to provide a sense of sequence. Using sine and cosine functions at different frequencies, each token gets a unique signal that tells the model its position in the sequence - much like page numbers in a book.
Residual Connections & Normalization
To build very deep models without the training pitfalls of vanishing gradients, Transformers use residual connections (adding the input of each layer back to its output) and layer normalization. These design choices ensure smoother, faster training and help stabilize the entire network.
🔸From RNNs to Today’s Giants
Early Days: RNNs and the Bottleneck Problem
Before Transformers, Recurrent Neural Networks (RNNs) - and their variants like LSTMs and GRUs - dominated sequence processing. These models read inputs sequentially and tried to remember context in a hidden state. However, they suffered from the long-range dependency problem: the further apart two related words are, the harder it is for an RNN to connect them.
The First Glimpse of Attention
Researchers like Bahdanau (2014) introduced attention to improve RNN-based models for machine translation. Instead of compressing the entire sentence into one fixed-size vector, the attention mechanism let the decoder dynamically “look back” at the encoder’s outputs.
The 2017 Breakthrough: “Attention Is All You Need”
Then came the seminal Transformer paper in 2017 by Vaswani et al. This work boldly claimed that by relying entirely on attention mechanisms - and discarding recurrences - the model could be made more effective and efficient. The result was a model that:
- Trains in parallel: No need to process tokens one by one.
- Handles long sequences gracefully: Every token can directly interact with every other token.
- Scales to large datasets and complex tasks: Laying the groundwork for massive language models.
Since then, Transformers have evolved rapidly. They’re now the foundation for models like BERT (which uses the encoder for understanding) and GPT (which uses the decoder for generating text), as well as for Vision Transformers (ViT) that bring attention to the world of images.
Modern Advancements
Transformers have branched into many domains:
- Language: GPT-3, GPT-4, ChatGPT, and BERT have transformed natural language processing, powering chatbots, search engines, and content generation.
- Vision: ViT and its variants, like the Swin Transformer, apply attention to image patches, challenging the dominance of traditional CNNs.
- Multimodal Tasks: Models now integrate text and vision, blurring the lines between different types of data.
Recent research continues to optimize Transformers further - exploring more efficient attention mechanisms, replacing parts of attention with simpler feed-forward networks, and integrating ideas from convolutional networks to make the models even more powerful and efficient.
🔸Why It Matters
Transformers have become the Holy Grail for sequence processing. They’ve revolutionized machine translation - making translations more accurate and context-aware, enabled massive language models - leading to breakthroughs in conversational AI and content generation, bridged domains - From text to images to audio, the principles of attention are being adapted across AI.
This architecture has fundamentally reshaped the landscape, setting the stage for future innovations that continue to push the boundaries of what machines can understand and create.