Understanding CLIP!
Published:
In recent years, the integration of computer vision and natural language processing has led to amazing advancements. One such innovation is OpenAI’s CLIP (Contrastive Language–Image Pre-training), which combines visual and textual understanding to tackle a variety of tasks without needing task-specific training. Here’s a comprehensive yet simplified exploration of CLIP’s inner workings, features, and transformative potential.
✅Core Features of CLIP
📌Contrastive Pre-Training with Natural Language Supervision
It was trained on an enormous dataset containing 400 million image-text pairs.
👉Using a contrastive learning approach, it aligns visual and textual representations through a symmetric loss function.
What is a contrastive learning you might wonder🤔? Its just a method where a model learns to identify similarities and differences in data. It compares three types of inputs:
✔️Anchor: The reference point or main item.
✔️Positive: An item similar to the anchor.
✔️Negative: An item different from the anchor.
The model learns to pull the anchor and positive closer together in the embedding space while pushing the negative further away.
Suppose we want to teach a model to recognize “oranges.”
The anchor could be a photo of an orange. The positive might be another image of an orange from a different angle. The negative could be an image of a watermelon. The model adjusts its internal representation so that the orange images are closer together, while the watermelon image is farther away.
👉Texts are processed using a Transformer-based encoder, with the final output capturing the essence of the description.
📌Zero-Shot Learning
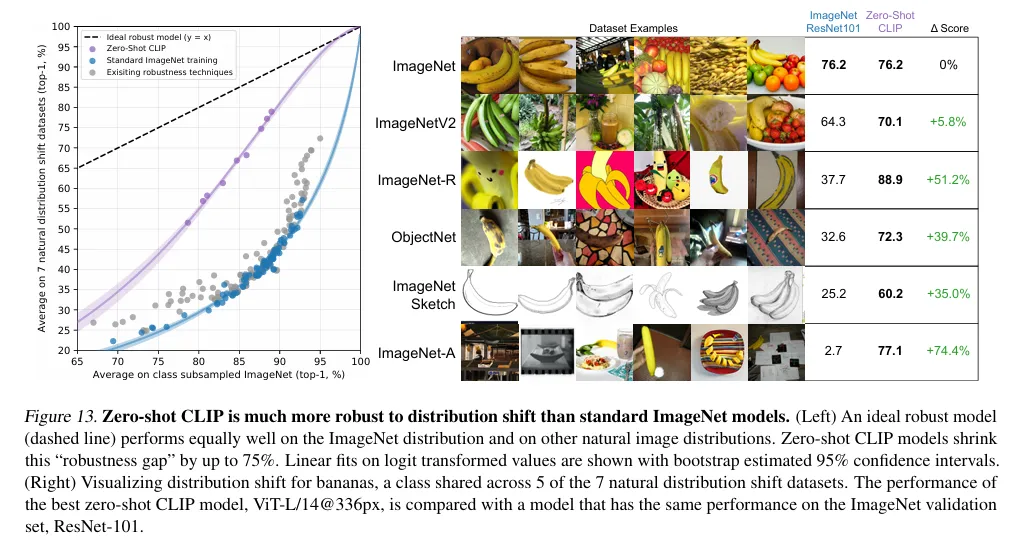
👉It excels in zero-shot image classification, meaning it can classify images into categories it has never seen before without additional training.
✔️For example, it can recognize animals, objects, or scenes simply by matching the image with textual prompts like “a photo of a pizza.”
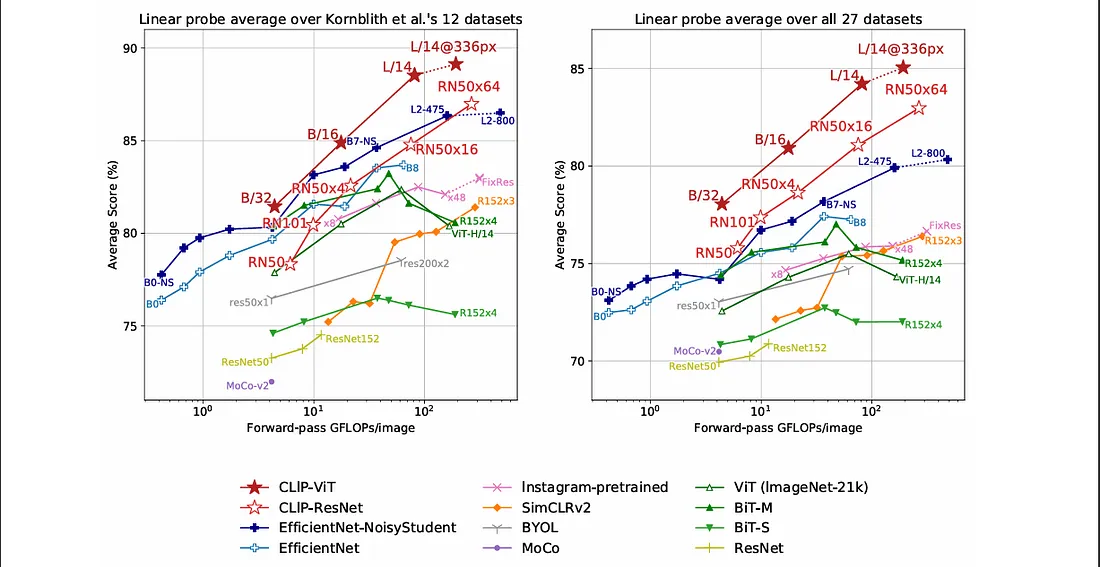
This figure👆 highlights how it requires fewer labelled examples to achieve performance comparable to traditional supervised models.
📌Scalability and Robustness
👉CLIP’s performance scales consistently with increased model size and compute resources, following a clear log-log linear trend.
👉Unlike standard ImageNet-trained models, CLIP demonstrates resilience to distribution shifts, performing well on datasets with different distributions or contexts.
📌Biases and Ethical Concerns
👉The authors acknowledge potential biases in CLIP, especially concerning sensitive attributes like gender or surveillance applications.
👉They highlight the importance of addressing these biases to ensure ethical deployment in real-world scenarios.
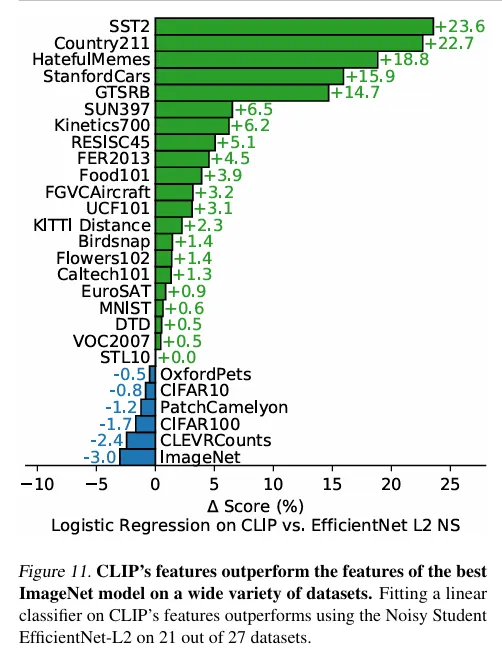
✅Simplified Explanation of CLIP’s Architecture
It uses a dual-encoder architecture with two main components: one for images and one for text. Both work together to map images and text into a shared space, enabling the model to understand their relationships.
📌Image Encoder
The image encoder extracts key features from images and converts them into high-dimensional vectors. Two architectures were explored:
✔️ResNet: A CNN-based model that processes images using convolutional layers to detect patterns like edges and textures.
✔️Vision Transformer (ViT): A model that processes images as sequences of patches, inspired by language modeling. ViT trains faster and requires fewer GPUs compared to ResNet.
Example: The largest ResNet (RN50x64) trained in 18 days on 592 GPUs, while the largest ViT trained in 12 days on 256 GPUs.
📌Text Encoder
The text encoder processes textual descriptions, converting them into high-dimensional vectors. It uses a Transformer-based architecture, widely known for its success in natural language processing (NLP), to capture the semantic meaning of text, with modifications for better alignment between text and images.
📌Shared Embedding Space:
Both the image and text encoders produce embeddings in a shared vector space. This allows the model to compare and understand the connections
✅Simplified Explanation of CLIP Training Process
📌Initial Attempt
The authors first tried building an image captioning model where the goal was to predict the exact caption for a given image, similar to other models like VirTex. However, this approach didn’t scale well for the 400 million image-text pairs.
📌Switch to Contrastive Learning
Instead of predicting captions, the authors used a contrastive learning approach to train CLIP. The goal of contrastive learning is to create an embedding space where similar pairs (e.g., an image of a “cat” and the caption “a picture of a cat”) are close together, and dissimilar pairs (e.g., “a picture of a dog”) are far apart.
📌CLIP’s Generalization
CLIP takes this further using a multi-class N-pair loss. Instead of one positive and one negative, it compares all possible (image, text) pairings in a batch. Out of N×NN \times NN×N possible pairs, only NNN are correct, and the model learns to maximize their similarity while minimizing the similarity of the incorrect pairs.
📌Training Steps
Images are processed by the image encoder, and text is processed by the text encoder. The embeddings are projected into the same space using a learned projection matrix. The embeddings are normalized to unit vectors. A matrix of dot products is calculated to measure similarities. The model is trained using a symmetric cross-entropy loss, ensuring embeddings for correct pairs are highly similar.
📌Instruction Tuning and model aggregation
The text encoder’s performance depends on the quality of the text input. Instead of just using single words like “cat,” the authors found that descriptive prompts such as “a photo of a cat” worked much better. For domain-specific tasks, tailored prompts improved results — for example, “a satellite photo of a city” for satellite imagery.
To further improve performance, the authors combined predictions from multiple prompts. For instance, they used 80 different prompts for ImageNet, boosting accuracy by 3.5%. Combining prompt engineering and ensembling improved ImageNet accuracy by nearly 5%.
✅Practical Applications
Multimodal Learning
It bridges the gap between text and images, making it a powerful component in systems that combine multiple data types.
It pairs well with generative models like DALL-E to create images from text or edit existing ones using instructions. Example: Change “a red car” to “a blue car” in an image by describing the desired edit.
Creative Applications
It powers tools for digital art and content creation. Example: Artists can generate or modify illustrations using prompts like “a futuristic city at sunset.”
Content Moderation
It can help identify inappropriate or harmful content on online platforms by analyzing images and matching them to descriptive rules. Example: It can flag an image with violent content or nudity based on a platform’s moderation guidelines.
Interpreting Low-Quality or Ambiguous Images
It can analyze unclear or low-resolution images and provide insights by matching them with text descriptions or similar images in its database. This capability is valuable in scenarios like surveillance, medical imaging, or forensic analysis.
Example: For a grainy security camera image, a user could ask, “Does this show a person holding an umbrella?” and CLIP might confirm based on its understanding of the visual content.
This approach helps fill in gaps in visual information, especially when clarity is compromised.
✅Limitations and Challenges
Limitations in Handling Long Texts
👉Challenges with lengthy inputs
👉Inability to process extended descriptions
👉Restricted text input capacity
Not a Generative Model
👉Absence of generative capabilities
👉Inability to create new content
👉Restricted to non-generative tasks
Lack of Explainability
👉Opaque decision-making
👉Limited transparency in outputs
👉Challenges in understanding model decisions
Weakness in Understanding Relationships and Abstract Concepts
👉Difficulty witt complex relationships
👉Limited comprehension of emotions and abstract ideas
👉Challenges in decoding nuanced interactions
Bias in Training Data
👉Inherited Data Biases
👉Ethical Concerns Due to Bias
👉Unintended Prejudices from Training Sets
Limited Fine-Grained Understanding
👉Weakness in Detailed Analysis
👉Challenges with Subtle Distinctions
👉Struggles in Handling Intricate Details
Limited Performance on Certain Tasks
👉Weak Generalization to Specialized Tasks
👉Suboptimal Results in Domain-Specific Use Cases
👉Inconsistent Performance Across Tasks
✅Future Directions
CLIP is revolutionizing multimodal learning, with exciting potential in fields like image recognition, natural language processing, medical diagnostics, assistive technologies, and robotics. Its ability to understand both text and images is paving the way for more intuitive human-AI interactions, making machines better at grasping context across different types of data.
Future research aims to address it’s current limitations, improve its interpretability, and unlock new applications.